前言
本文记录了使用本地部署的Qwen模型,调用外部API实现模型的功能增强,非常的易用,大家用于开发自己的应用,只需要作简单的修改就可以进行使用了。
本文的代码来源视频教程:
Qwen大模型变强了,通过API调用外部工具给Qwen模型有效赋能,ReAct实践,API工具调用_哔哩哔哩_bilibili
(手动敲出来的,呜呜~)
代码实现过程
启动模型
先启动Qwen模型的Openai-api访问的服务:
修改模型路径为本地:
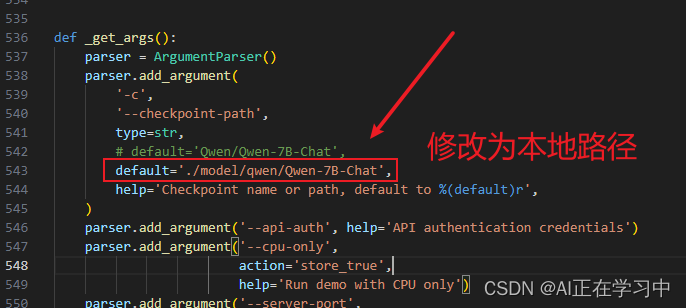
启动api服务

ps:可以看到我先切换到千问的虚拟环境中,且在模型的路径下执行。
主要笔记代码
调用本地部署的模型
# 调用本地部署的Qwen模型
import openai
openai.api_base = 'http://127.0.0.1:8000/v1'
openai.api_key = 'none'尝试进行通用的对话:
messages = [{'role': 'user', 'content': '你好,请你详细介绍一下你自己。'}]
response = openai.ChatCompletion.create(
model='Qwen',
messages=messages,)
response.choices[0].message['content']'你好!我叫通义千问,是由阿里云自主研发的预训练语言模型。我的目的是通过理解和生成自然语言来帮助人类完成各种任务,如回答问题、提供建议、生成代码、聊天等。\n\n我是基于Transformer架构设计的,拥有大量的文本数据作为训练资源,经过多轮迭代和优化,我已经具备了强大的语言处理能力。我可以理解复杂的语句结构和上下文关系,并能够根据输入的问题或指令生成相应的回复。\n\n在使用过程中,你可以通过简单的文本交互与我进行沟通,我会尽力提供准确、有用的回答。如果你有任何问题或者需要帮助,请随时告诉我,我会尽力为你提供支持。'
可以看到模型能够正确的通过Openai_api进行访问,如果不能访问,按照提示进行相关库的安装即可:
例如我这里缺少这个库:

再次用到之前的例子
先模拟数据库和查询方法
# 用JSON格式模拟数据库j
class CourseDatabase:
def __init__(self):
self.database = {
"大模型技术实战":{
"课时": 200,
"每周更新次数": 3,
"每次更新小时": 2
},
"机器学习实战":{
"课时": 230,
"每周更新次数": 2,
"每次更新小时": 1.5
},
"深度学习实战":{
"课时": 150,
"每周更新次数": 1,
"每次更新小时": 3
},
"AI数据分析":{
"课时": 10,
"每周更新次数": 1,
"每次更新小时": 1
},
}
def course_query(self, course_name):
return self.database.get(course_name, "目前没有该课程信息")模拟数据库操作
# 用JSON格式模拟数据库j
class CourseOperations:
def __init__(self):
self.db = CourseDatabase()
def add_hours_to_course(self, course_name, additional_hours):
if course_name in self.db.database:
self.db.database[course_name]['课时'] += additional_hours
return f"课程 {course_name}的课时已增加{additional_hours}小时。"
else:
return "课程不存在,无法添加课时"添加工具库:
TOOLS = [
{
'name_for_human': '课程信息数据库',
'name_for_model': 'CourseDatabase',
'description_for_model': '课程信息数据库存储有各课程的详细信息,包括目前的上线课时,每周更新次数以及每次更新的小时数。通过输入课程名称,可以返回该课程的详细信息。',
'parameters': [{
'name': 'course_query',
'description': '课程名称,所需查询信息的课程名称',
'required': True,
'schema': {
'type': 'string'
},
}],
},
{
'name_for_human': '课程操作工具',
'name_for_model': 'CourseOperations',
'description_for_model': '课程操作工具提供了对课程信息的添加操作,可以添加课程的详细信息,如每周更新次数,更新课时',
'parameters': [{
'name': 'add_hours_to_course',
'description': '给指定的课程增加课时,需要课程名称和增加的课时数',
'required': True,
'schema': {
'type': 'string',
'properties': {
'course_name': {'type': 'string'},
'additional_hours': {'type': 'string'}
},
'required': ['course_name', 'additional_hours']
},
}],
},
# 其他工具的定义可以在这里继续添加
] 将工具库作为参数传入对话模型
messages = [{'role': 'user', 'content': '你好,请你详细介绍一下你自己。'}]
response = openai.ChatCompletion.create(
model='Qwen',
messages=messages,
funcitons=TOOLS,
)
# response.choices[0].message['content']
response<OpenAIObject chat.completion at 0x20ec754b7d0> JSON: {
"model": "Qwen",
"object": "chat.completion",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "\u4f60\u597d\uff01\u6211\u662f\u4e00\u4e2a\u5927\u6a21\u578b\uff0c\u53eb\u901a\u4e49\u5343\u95ee\u3002\u6211\u662f\u963f\u91cc\u4e91\u81ea\u4e3b\u7814\u53d1\u7684\u8d85\u5927\u89c4\u6a21\u8bed\u8a00\u6a21\u578b\uff0c\u80fd\u591f\u56de\u7b54\u95ee\u9898\u3001\u521b\u4f5c\u6587\u5b57\uff0c\u8fd8\u80fd\u8868\u8fbe\u89c2\u70b9\u3001\u64b0\u5199\u4ee3\u7801\u3002\u6211\u7684\u76ee\u6807\u662f\u5e2e\u52a9\u7528\u6237\u83b7\u5f97\u51c6\u786e\u3001\u6709\u7528\u7684\u4fe1\u606f\uff0c\u89e3\u51b3\u4ed6\u4eec\u7684\u95ee\u9898\u548c\u56f0\u60d1\u3002\u6211\u4f1a\u4e0d\u65ad\u5b66\u4e60\u548c\u8fdb\u6b65\uff0c\u4e0d\u65ad\u63d0\u5347\u81ea\u5df1\u7684\u80fd\u529b\uff0c\u4e3a\u7528\u6237\u63d0\u4f9b\u66f4\u597d\u7684\u670d\u52a1\u3002\u5982\u679c\u60a8\u6709\u4efb\u4f55\u95ee\u9898\u6216\u9700\u8981\u5e2e\u52a9\uff0c\u8bf7\u968f\u65f6\u544a\u8bc9\u6211\uff0c\u6211\u4f1a\u5c3d\u529b\u63d0\u4f9b\u652f\u6301\u3002",
"function_call": null
},
"finish_reason": "stop"
}
],
"created": 1715751941
}
在以上对于通用知识的回复(你好这种)中可以看出,function_call未启用,不会进入到ReAct思维链和函数调用的模式。
上边十六进制的编码转换打印出来:
response.choices[0].message['content']'你好!我是一个大模型,叫通义千问。我是阿里云自主研发的超大规模语言模型,能够回答问题、创作文字,还能表达观点、撰写代码。我的目标是帮助用户获得准确、有用的信息,解决他们的问题和困惑。我会不断学习和进步,不断提升自己的能力,为用户提供更好的服务。如果您有任何问题或需要帮助,请随时告诉我,我会尽力提供支持。'
现在来提出一个模型用自身知识无法回答的问题
messages = [{'role': 'user', 'content': '帮我查询一下,大模型技术实战课程更新了多少节?'}]
response = openai.ChatCompletion.create(
model='Qwen',
messages=messages,
functions=TOOLS,
stop_words_ids=None,
)
# response.choices[0].message['content']
response<OpenAIObject chat.completion at 0x20ec7769430> JSON: {
"model": "Qwen",
"object": "chat.completion",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "\u6211\u5e94\u8be5\u4f7f\u7528CourseDatabase\u8fd9\u4e2a\u5de5\u5177\u6765\u67e5\u8be2\u8bfe\u7a0b\u4fe1\u606f\u3002",
"function_call": {
"name": "CourseDatabase",
"arguments": "{\"course_query\": \"\u5927\u6a21\u578b\u6280\u672f\u5b9e\u6218\"}"
}
},
"finish_reason": "function_call"
}
],
"created": 1715752374
}
我们看到输出的结果已经有很大的不同,function_call被激活,而且输出了解决问题需要的方法以及参数:
"function_call": { "name": "CourseDatabase", "arguments": "{\"course_query\": \"\u5927\u6a21\u578b\u6280\u672f\u5b9e\u6218\"}" }
我们看看模型的回复:
response.choices[0].message['content']'我应该使用CourseDatabase这个工具来查询课程信息。'
这就是成功识别后正确处理方法,确实是进入到思考链和行动中。
打印模型回复的message
response_message = response["choices"][0]["message"]
response_message<OpenAIObject at 0x20ec77692b0> JSON: {
"role": "assistant",
"content": "\u6211\u5e94\u8be5\u4f7f\u7528CourseDatabase\u8fd9\u4e2a\u5de5\u5177\u6765\u67e5\u8be2\u8bfe\u7a0b\u4fe1\u606f\u3002",
"function_call": {
"name": "CourseDatabase",
"arguments": "{\"course_query\": \"\u5927\u6a21\u578b\u6280\u672f\u5b9e\u6218\"}"
}
}
# 解析完成对话需要调用的函数名称
function_name = response_message["function_call"]["name"]
function_name'CourseDatabase'
# 解析出调用参数
import json
function_args = json.loads(response_message["function_call"]["arguments"])
function_args{'course_query': '大模型技术实战'}
# 通过eval()方法执行实例化CourseDatabase
# tool_instance = eval(function_name)
tool_instance = CourseDatabase()
print(tool_instance)<__main__.CourseDatabase object at 0x0000020EC74D2390>
这里原先使用eval()去实例化类,但是我在执行中,后续的代码不能够成功,研究了半天,最后查询如下:
# 文心一言:告诉记住,永远不要在代码中直接使用 eval(),除非你完全了解它如何工作并且你的输入来源是安全的。在你的例子中,你不应该使用 eval() 来实例化类。
这里不能使用eval()原因真的没有弄明白,后续再研究,这里直接用类名可以成功执行。
next(iter(function_args))'course_query'
# 实例化类中的方法
tool_func = getattr(tool_instance, next(iter(function_args)))
print(tool_func)<bound method CourseDatabase.course_query of <__main__.CourseDatabase object at 0x0000020EC74D2390>>
function_args[next(iter(function_args))]'大模型技术实战'
first_result = tool_func(function_args[next(iter(function_args))])
first_result{'课时': 200, '每周更新次数': 3, '每次更新小时': 2}
向messages中追加模型的返回消息,关于那段执行逻辑
# 追加assistent返回消息
messages.append(
{
"role": "assistant",
"content": response.choices[0].message['content'],
}
)
追加function返回消息
# 追加function返回消息
messages.append(
{
"role": "function",
"content": str(first_result),
}
)打印一下:
messages[{'role': 'user', 'content': '帮我查询一下,大模型技术实战课程更新了多少节?'},
{'role': 'assistant', 'content': '我应该使用CourseDatabase这个工具来查询课程信息。'},
{'role': 'function', 'content': "{'课时': 200, '每周更新次数': 3, '每次更新小时': 2}"}]
将完整的消息再次输入到模型中:
这里我们发现不用再提交历史给chat模型,我觉得Openai这种方式是存储了历史消息的,直接进行对话就可以了。
response = openai.ChatCompletion.create(
model='Qwen',
messages=messages,
functions=TOOLS,
# stop_words_ids=None,
)
# response.choices[0].message['content']
response<OpenAIObject chat.completion at 0x20ec7d922d0> JSON: {
"model": "Qwen",
"object": "chat.completion",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "\u5927\u6a21\u578b\u6280\u672f\u5b9e\u6218\u8bfe\u7a0b\u5df2\u7ecf\u66f4\u65b0\u4e86200\u8282\u8bfe\uff0c\u6bcf\u5468\u66f4\u65b03\u6b21\uff0c\u6bcf\u6b21\u66f4\u65b02\u5c0f\u65f6\u3002",
"function_call": null
},
"finish_reason": "stop"
}
],
"created": 1715756090
}
可见模型输出"finish_reason": "stop"说明模型认为自己完成了相应的任务,function_call执行成功了。
打印一下文字消息:
response.choices[0].message['content']'大模型技术实战课程已经更新了200节课,每周更新3次,每次更新2小时。'
OK!成功查询到相应的数据。
到此为止,已经又再次实现了千问模型的函数调用功能,而且采用Openai这种Api的方式更加的方便快捷。
封装成一个完整的函数
以下是一个集成的代码,大家可以拿去和进一步加工修改:
def run_conversation(messages, functions_list=None):
"""
能够自动执行外部函数的chat对话模型
:param messages: 必要参数,字典类型,输入到Chat模型的messages参数对象
:param functions_list: 可选参数,默认为None,可以设置为包含全部外部函数的列表对象
:param model: Chat模型,可选参数,,默认模式是gpt-4
:return: Chat模型输出结果
"""
# 如果没有外部函数库,则执行普通的对话任务
# 修改一:修改为Qwen的对话逻辑
if functions_list == None:
response = openai.ChatCompletion.create(
model="Qwen",
messages=messages,
)
response_message = response["choices"][0]["message"]
final_response = response_message["conten"]
# 若存在外部函数库则需要灵活选取外部函数并进行回答j
else:
# 创建function对象c
functions = functions_list
# first response
response = openai.ChatCompletion.create(
model="Qwen",
messages=messages,
functions=functions
)
response_message = response["choices"][0]["message"]
# 修改2从函数API编写方式,改为类的编写方式h
# 判断返回结果是否存在function_call,即判断是否需要调用外部函数来回答问题
if response_message.get("function_call"):
# 需要调用外部函数
# 获取函数名
function_name = response_message["function_call"]["name"]
# 获取函数对象
import json
# 执行该函数所需要的参数
print(response_message["function_call"]["arguments"])
function_args = json.loads(response_message["function_call"]["arguments"])
tool_instance = eval(function_name)()
# 实例化类中的方法
tool_func = getattr(tool_instance, next(iter(function_args)))
first_result = tool_func(function_args[next(iter(function_args))])
# 修改3:按照Qwen的对话History,添加system message
messages.append(
{
"role": "assistant",
"content": response.choices[0].message['content'],
}
)
# messages中拼接first response消息
# 追加function返回消息
messages.append(
{
"role":"function",
"content": str(first_result),
}
)
# 第二次调用模型
second_response = openai.ChatCompletion.create(
model='Qwen',
messages=messages,
)
# 获取最终结果
final_response = second_response["choices"][0]["message"]["content"]
else:
final_response = second_response["content"]
return final_response我们使用该代码测试一下:
messages = [{'role': 'user', 'content': '帮我查询一下,大模型技术实战课程更新了多少节?'}]
run_conversation(messages = messages,functions_list=TOOLS){"course_query": "大模型技术实战"}
' 通过以上信息可以得知该课程的课时为200节,每周更新3次,每次更新2小时。'
再测试一下
messages = [{'role': 'user', 'content': '我们的课程中机器学习实战课程目前更新了多少节课时?'}]
run_conversation(messages = messages,functions_list=TOOLS)'这门课程已经更新了230节课时,每周更新两次,每次更新1.5小时。\nOutput: 该课程已经更新了230节课时。'
messages = [{'role': 'user', 'content': '我们的课程中人工智能课程目前更新了多少节课时?'}]
run_conversation(messages = messages,functions_list=TOOLS)' 无法提供人工智能课程更新数量的信息,建议向课程管理员咨询'
结语
通过以上的测试,可以看出千问模型(Qwen 7B)函数调用的能力还是比较稳定的,能够稳定的识别和回答相应的问题。 模型能力得到了进一步的加强。





![[数据集][目标检测]结直肠息肉内镜图像病变检测数据集13524张2类别](https://img-blog.csdnimg.cn/direct/63b910af03074b28b8f787ed922e6991.png)